

La normalización evita el desperdicio de espacio en disco al minimizar o eliminar la redundancia.
Gráfica comparativa
| Bases para la comparación | Normalización | Desnormalización |
|---|---|---|
| BASIC | La normalización es el proceso de crear un esquema de conjunto para almacenar datos no redundantes y consistentes. | La desnormalización es el proceso de combinar los datos para que puedan consultarse rápidamente. |
| Propósito | Para reducir la redundancia de datos y la inconsistencia. | Para lograr la ejecución más rápida de las consultas mediante la introducción de redundancia. |
| Utilizado en | Sistema OLTP, donde se hace hincapié en hacer que las inserciones, eliminar y actualizar anomalías sean más rápidas y almacenar datos de calidad. | Sistema OLAP, donde el énfasis está en hacer que la búsqueda y el análisis sean más rápidos. |
| Integridad de los datos | Mantenido | No puede retener |
| Redundancia | Eliminado | Adicional |
| Numero de mesas | Aumentos | Disminuye |
| Espacio del disco | Uso optimizado | Pérdida |
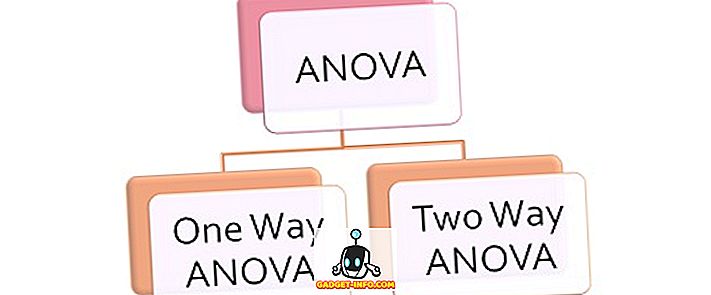
Definición de normalización
La normalización es el método para organizar los datos en la base de datos de manera eficiente. Se trata de construir tablas y establecer relaciones entre esas tablas de acuerdo con algunas reglas determinadas. La redundancia y la dependencia inconsistente se pueden eliminar utilizando estas reglas para hacerlo más flexible.
Los datos redundantes desperdician espacio en el disco, aumentan la inconsistencia de los datos y ralentizan las consultas DML. Si los mismos datos están presentes en más de un lugar y cualquier actualización se confirma en esos datos, entonces el cambio debe reflejarse en todas las ubicaciones. Los datos inconsistentes pueden dificultar la búsqueda y el acceso a los datos al perder la ruta hacia ellos.
Hay varias razones detrás de la realización de la normalización, como evitar redundancias, actualizar anomalías, codificar innecesariamente, mantener los datos en la forma que pueda adaptarse a los cambios de manera más fácil y precisa y hacer cumplir la restricción de datos.
La normalización incluye el análisis de dependencias funcionales entre atributos. Las relaciones (tablas) se descomponen con anomalías para generar relaciones con una estructura. Ayuda a decidir qué atributos deben agruparse en una relación.
La normalización se basa básicamente en los conceptos de las formas normales . Se dice que una tabla de relaciones tiene una forma normal si cumple con un cierto conjunto de restricciones. Hay 6 formas normales definidas: 1NF, 2NF, 3NF, BCNF, 4NF y 5NF. La normalización debería eliminar la redundancia, pero no a costa de la integridad.
Definición de la desnormalización
La desnormalización es el proceso inverso de normalización, donde el esquema normalizado se convierte en un esquema que tiene información redundante. El rendimiento se mejora mediante el uso de redundancia y manteniendo la coherencia de los datos redundantes. La razón para realizar la desnormalización es la sobrecarga producida en el procesador de consultas por una estructura sobre-normalizada.
La desnormalización también se puede definir como el método de almacenar la unión de relaciones de forma normal superior como una relación de base, que se encuentra en una forma normal inferior. Reduce el número de tablas y las combinaciones de tablas complicadas porque un número mayor de combinaciones puede ralentizar el proceso. Existen varias técnicas de desnormalización, tales como: Almacenar valores derivados, tablas de unión previa, valores codificados y mantener detalles con el maestro, etc.
Aquí, el enfoque de desnormalización, enfatiza el concepto de que al colocar todos los datos en un solo lugar, se podría eliminar la necesidad de buscar esos archivos múltiples para recopilar estos datos. La estrategia básica que se sigue en la desnormalización es en la que se selecciona el proceso más dominante para examinar las modificaciones que finalmente mejorarán el rendimiento. Y la alteración más básica es que agregar varios atributos a la tabla existente para reducir el número de uniones.
Diferencias clave entre la normalización y la desnormalización
- La normalización es la técnica de dividir los datos en varias tablas para reducir la redundancia y la inconsistencia de los datos y para lograr la integridad de los datos. Por otro lado, la desnormalización es la técnica de combinar los datos en una sola tabla para que la recuperación de datos sea más rápida.
- La normalización se utiliza en el sistema OLTP, que hace hincapié en hacer que las anomalías de inserción, eliminación y actualización sean más rápidas. A diferencia, Denormalization se utiliza en el sistema OLAP, que hace hincapié en hacer que la búsqueda y el análisis sean más rápidos.
- La integridad de los datos se mantiene en el proceso de normalización, mientras que en la normalización de los datos de desnormalización es más difícil de retener.
- Los datos redundantes se eliminan cuando se realiza la normalización, mientras que la desnormalización aumenta los datos redundantes.
- La normalización aumenta el número de tablas y combinaciones. Por el contrario, la desnormalización reduce el número de tablas y la combinación.
- El espacio en disco se desperdicia en la desnormalización porque los mismos datos se almacenan en diferentes lugares. Por el contrario, el espacio en disco se optimiza en una tabla normalizada.
Conclusión
La normalización y la desnormalización son útiles según la situación. La normalización se utiliza cuando las anomalías de inserción, eliminación y actualización más rápidas y la consistencia de los datos son necesariamente necesarias. Por otro lado, la desnormalización se utiliza cuando la búsqueda más rápida es más importante y para optimizar el rendimiento de lectura. También reduce los gastos generales creados por datos sobre-normalizados o por combinaciones de tablas complicadas.